
编译参数
-o 好像是可以给生成的 .exe 命名。
-Wall -Wextra -g3 -Wl,--stack=81920000 -O2 -pipe实时报错

命令窗口运行cpp文件
1.
cd 指定文件目录
2.
g++ xxx.cpp
3.
./a.out或者./a.exe
因为生成的文件可能不同。
关键字
命名:避免关键字,以字母或者下划线开头,后面包含字母、下划线、数字。

数据类型

宏定义
typedef

ifdef
语法:

#define A
..
#ifdef A
//程序段1
#else
//程序段2
#endif A判断某个量是否被宏定义,如果是则执行语句。
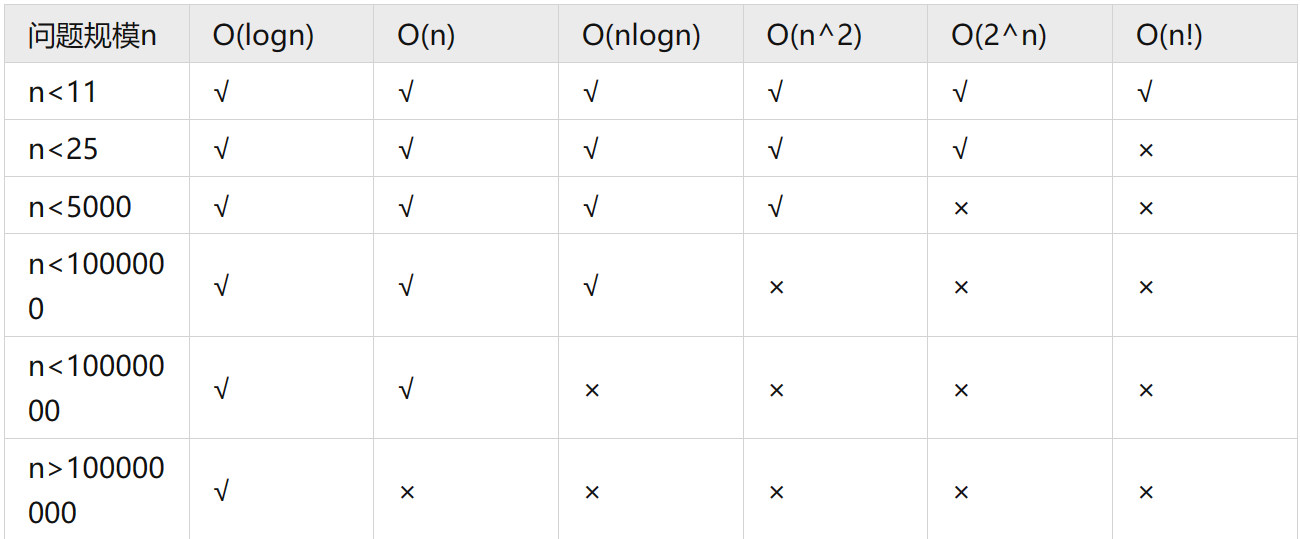
时间复杂度
结构体构造函数
struct node
{
int v,u,op;
node(){}
node(int a,int b,int c):v(a),u(b),op(c){}
}struct node
{
int v,u,op;
node(){}
node(int a,int b,int c){v=a;u=b;op=c;}
}结构体重载运算符
内部
传两个参数,需要friend定义
struct Point
{
int x, y;
friend bool operator < (Point a, Point b)
{//为两个结构体参数,结构体调用一定要写上friend
if(a.x == b.x)
return a.y < b.y;
return a.x < b.x;//按x从小到大排
}
};
成员函数,只传一个参数
struct Point
{
int x, y;
bool operator < (const Point &a) const
{//直接传入一个参数,不必要写friend
if(x == a.x)
return y < a.y;
return x < a.x;//按x升序排列
}
};这里自己是作为第一个参数,符号后面的是传进来的第二个参数。
例如,对于这样一串代码:
#include<bits/stdc++.h>
using namespace std;
struct node
{
int x, y;
const node operator + (const node &a) const
{
return {x + a.x, y + a.y};
}
};
int main()
{
const node n = {3, 5};
const node m = {1, 8};
node ans = n + m;
cout << ans.x << endl << ans.y << endl;
return 0;
}- 第一个 const :代表返回值是常量无法被修改。
- 这时候把它去掉,
(n + m) = {1, 1};的写法是合法的。
- 这时候把它去掉,
- 第二个 const :代表传入的参数可以是常量,相当于允许常量参数的传入。
- 这时候如果把它去掉,由于参数 m 是一个常量,无法传入导致报错。
- 第三个 const :代表调用函数的可以是一个常量,同第二个。
- 这个时候把它去掉,由于调用函数的 n 是一个常量,因此会报错。
n + m 相当于 n.operator+(m)
全部:
#include<bits/stdc++.h>
using namespace std;
struct node
{
int x, y;
const node operator + (const node &a) const
{
return {x + a.x, y + a.y};
}
const node operator - (const node &a) const
{
return {x - a.x, y - a.y};
}
const node operator - () const
{
return {-x, -y};
}
void operator += (const node &a)
{
x += a.x;
y += a.y;
}
void operator -= (const node &a)
{
x -= a.x;
y -= a.y;
}
bool operator == (const node &a) const
{
return x == a.x && y == a.y;
}
bool operator != (const node &a) const
{
return x != a.x || y != a.y;
}
void operator ++ ()
{
++x;
++y;
}
const node operator ++ (int) //固定格式,不是很懂
{
node old = {x, y};
x++;
y++;
return old;
}
void operator -- ()
{
--x;
--y;
}
const node operator -- (int) //固定格式,不是很懂
{
node old = {x, y};
x--;
y--;
return old;
}
};
/*由于<<左侧必须是cout,因此不可作为成员函数进行重载,必须写在全局区,也可通过与友元函数相结合来实现目的*/
ostream &operator << (ostream &out, const node &a) // 注意返回值为引用类型的输出流
{
out << a.x << ' ' << a.y;
return out;
}
istream &operator >> (istream &in, node &a) // 由于是读入,所以参数不能为常量
{
in >> a.x >> a.y;
return in;
}
int main()
{
const node n = {3, 5};
const node m = {1, 8};
node ans = n + m;
cout << ans.x << ' ' << ans.y << endl;
ans = n - m;
cout << ans.x << ' ' << ans.y << endl;
ans = -ans;
cout << ans.x << ' ' << ans.y << endl;
ans += {10, 10};
cout << ans.x << ' ' << ans.y << endl;
ans -= {5, 5};
cout << ans.x << ' ' << ans.y << endl;
cout << (n == m) << ' ';
cout << (n != m) << ' ';
cout << ans++.x << ' ' << ans.y << endl;
cout << ans--.x << ' ' << ans.y << ' ' << ans.x << endl;
cout << ans << endl;
node ano;
cin >> ano;
cout << ano << endl;
return 0;
}外部
堆排序规则
//定义的比较结构体
//注意:cmp是个结构体
struct cmp
{//自定义排序规则
bool operator()(const Point& a,const Point& b)
{
if(a.x == b.x)
return a.y < b.y;
return a.x < b.x; //将小于号比较规则替换为结构体x比较规则
}//如果要升序改变不等号方向就好
};
//初始化定义
priority_queue<Point,vector<Point>, cmp> q;
函数排序规则
struct Point
{
int x, y;
}p[1005];
bool cmp(Point a, Point b)
{
if(a.x == b.x)
return a.y < b.y;
return a.x < b.x;
}
sort(p + 1, p + 1 + 1000, cmp);
读入EOF
注:
cin无法读取EOF

~作用是将这个数变成它的相反数后再减一。
那么EOF读进来后就变成了0,循环就终止了,但是如果是普通的-1,不会让循环终止。
数组传参
int x[100];
int get(int a[])
{
a[1]+=1;
//blabla...
}
int main()
{
get(x);
cout<<x[1];
}比如这里就可以把数组传进去
这里的为数组名字,实际上传进去的是数组首元素的指针,get接受的是指针,就可以根据下标访问该数组中的元素,所以这里不用加取地址&符也可以(是不能加,对一个指针取地址是什么啊)。
这里特意用了这另一个名字,这样就可以明显得看出它访问的是传入数组的地址而不是全局变量里的地址。
而传入数组地址时,编译器是不知道该数组是多大的,所以一般我们会把该数组的大小以int类型传入。
而数组大小可以用该式子得出:
int lenth=sizeof(x)/sizeof(x[0]);sizeof函数返回的是该数据的字节大小,比如sizeof(int)返回的是4,因为int是四个字节。
被除数写上数组,除数写上数组中某一个值,这样得到的就是数组的长度了。
文件读入/输出
freopen("xxx.in","r",stdin);
freopen("xxx.out","w",stdout);sscanf&sprintf
sscanf(str,"%d",x);
sprintf(str,"%d",x);表示从一个字符串中读入。
表示输出到一个字符串中。
文件和流
首先我们熟知的
cin和cout是iostream标准库中的分别用于从标准输入读取和向标准输出写入流
其次就是今天要说的从文件读取和向文件写入流,需引用fstream库。
其中定义了三种新的数据类型:
ofstream:输出文件流,用于创建文件和向文件中写入信息。ifstream:输入文件流,用于从文件中读取信息。fstream:文件流,具有上述两种功能。
对象函数
open()函数:
第一个参数为双引号下的字符串,表示文件路径即名称。
第二个参数为打开模式:

可以用|符号相间表示两个同时启用。
close()函数:
关闭文件。
写入文件:
类似cin cout ,即>> <<。
例子:
#include <fstream>
#include <iostream>
using namespace std;
int main ()
{
char data[100];
// 以写模式打开文件
ofstream outfile;
outfile.open("afile.dat");
cout << "Writing to the file" << endl;
cout << "Enter your name: ";
cin.getline(data, 100);
// 向文件写入用户输入的数据
outfile << data << endl;
cout << "Enter your age: ";
cin >> data;
cin.ignore();
// 再次向文件写入用户输入的数据
outfile << data << endl;
// 关闭打开的文件
outfile.close();
// 以读模式打开文件
ifstream infile;
infile.open("afile.dat");
cout << "Reading from the file" << endl;
infile >> data;
// 在屏幕上写入数据
cout << data << endl;
// 再次从文件读取数据,并显示它
infile >> data;
cout << data << endl;
// 关闭打开的文件
infile.close();
return 0;
}命名空间
我们比较熟悉的命名空间,比如 using namespace std
这时候我们访问命名空间内的变量就可以像全局一样访问了。
命名空间可以嵌套:
namespace A {
int a = 100;
namespace B {
...
}
}命名空间是开放的,可以随时添加而不会覆盖:
namespace A {
int a = 100;
namespace B {
...
}
}
namespace A {
int b = 100;
}命名空间内可以存储变量和函数。
命名空间内的函数和变量也可以在命名空间外定义,当然,要加上 ::
无命名空间(没有名字),那么里卖弄的东西只可以在本文件内访问。
也可以通过赋值的方式取别名。
随机化
rand()函数会返回零到最大随机数的任意整数。
- :
rand()%100 - :
rand()%100+1 - :
rand()%(b-a+1)+a
rand()函数每次随机都是产生相同的随机数,若要不同,可以用srand(seed)来随机化种子。
也可以引用srand(time(0))来使用当前时间使随机数发生随机化,两次程序运行时间间隔超过一秒。
高性能
mt19937
范围是 unsigned int
mt19937 rd(time(0));
int a=rd();为一个类型,变量名后面的括号代表种子。
另一种方法:
ll Rand(ll mod)
{
ll ans = INT_MAX;
return ans * rand() % mod + 1;
}原码反码补码
原码
计算机字长为8位,二进制数最高位表示符号位,0为正,1为负。
原码即二进制表示。
但是按照原码进行正负数的二进制加减显然得到的是错误的答案。
于是就有了反码。
反码
正数不变,负数除了符号位每位取反,即反码。
但是这样会出现两种,即10000000和00000000。
为了避免这种情况出现,于是出现了补码。
补码
整数不变,负数在反码的基础上+1.
这样就可以把多出的一位进掉,变成“第九位”,而第九位不在计算机的字长里,这样就可以很好的规避两种的问题。
auto类型
当我们定义一个迭代器的时候,我们通常要这样写:
map<int,string> m;
map<int,string>::iterator it;
it=m.begin();这样就很麻烦,所以我们可以简单地写为:
map<int,string> m;
auto it=m.begin();auto会自动识别该元素的类型。
需要注意的是:用auto定义的这一行必须是同种类型,下面举出反例:
auto a=1,b=1.0,c="abc";这样是过不了编译的。
指针
数组名其实就是一个指针常量,它指向数组的首元素。
定义:
int *p;*最好加在变量名旁边,因为不会产生误解比如:
int *a,*b,*c;这样定义的是三个指针,而这样:
int *a,b,c;这样仅 为指针。
使用
通过*a来访问该地址的值,指针储存的为地址,所以我们可以这样赋值:
int num,*a;
a=#
cout<<*a;其中&为取地址,返回值为的地址。
取地址
&还有一个功能,那就是起别名,称为引用。
引用应加在变量名前而非类型名后。
因此在逗号定义中要写多个。
比如下面这串代码:
#include<bits/stdc++.h>
using namespace std;
int main()
{
// int *a,*b,*c;
// cout<<a<<b<<c;
int val = 7, val2 = 999;
int &refval = val, &refval2 = val2; //引用必须要初始化,使其绑定到一个变量上
//修改引用的值将改变其所绑定的变量的值
refval = -12;
printf("%d %d\n", val, refval);//-12,refval的值和val一样
//将引用b赋值给引用a将改变引用a所绑定的变量的值,
//引用一但初始化(绑定),将始终绑定到同一个特定对象上,无法绑定到另一个对象上
refval = refval2;
printf("%d %d\n", val, refval);//999
return 0;
} 输出为:
-12 -12
999 999相当于windows系统下的mklink命令,相当于可以直接修改文件原内容的快捷方式。
在上述例子中,refval是val的别名,refval2 是val2 的别名。
修改别名就相当于修改元素本身。
字符串的读入
对于字符的二维数组,我们可以这样读入:
char c[N][N];
...
for(int i=1;i,=n;i++)
scanf("%s",c[i]);String 初始化
1.
string str1 = "test01" ;2.
string( size_type length, char ch );
string str2( 5, 'c' ); // str2 'ccccc'3.
string( const char *str );
string str3( "Now is the time..." );4.
string( string &str, size_type index, size_type length );
- 以
index为索引开始的子串,长度为length, 或者以从start到end的元素为初值.。
string str4( str3, 11, 4 ); //str4 "time"eg.
#include <iostream>
using namespace std;
int main() {
string str1 = "test01" ;
string str2( 5, 'c' ); // str2 'ccccc'
string str3( "Now is the time..." );
string str4( str3, 11, 4 );
cout << str1 << endl;
cout << str2 << endl;
cout << str3 << endl;
cout << str4 << endl;
return 0;
}输出:
test01
ccccc
Now is the time...
time清除
str.clear();迭代器的辅助函数
#include<algorithm>
注: .begin()指向的是容器首个元素的迭代器,.end()指向的是容器末尾的下一个元素的迭代器,因此是左开右闭得一个区间。
1.
advance(iterator,int)
例如advance(it,6)就是使it这个迭代器向后移动6个元素(++六次)。
advance(it,-6)就是使it这个迭代器向前移动6个元素。
2.
distance(it1,it2)计算两个迭代器之间的距离(从it1到it2需要++多少次)。
若it2在it1前面,那么会进入死循环。
3.
iter_swap(it1,it2)交换两个迭代器的值。
反向迭代器
倒着遍历
for(vector<int>::reverse_iterator it=b.rbegin();it!=b.rend();it++)这里++表示向前一个元素,--表示向后一个元素。
也可以这样写:
for(auto it=b.rbegin();it!=b.rend();it++)范围for
for(auto &i:a)第一个参数表示遍历声明,即声明的变量,被遍历到的元素会储存到这个变量中,相当于拷贝一份,若加上&,则可以直接引用并修改元素。
第二个参数为遍历对象,常见为各种容器(map,vector,set,list等),数组,填入它们的名称即可;
若防止元素被修改,可以这样写:
for(const auto &i:a)这里加入&是为了防止拷贝导致运行变慢。
对于关系型容器比如map,有几点要注意:
对于map的迭代器遍历:for(auto i=m.begin())识别i为迭代器,则访问就要用迭代器的方式:
i->first;
i->second;而对于范围for,for(auto i:m)识别i为容器中的value_type,这里相当于pair,访问就要用pair的方式:
i.first;
i.second;若识别到的元素不可被修改,为只读模式,那么就会被视为const auto &,例如set
冒号后面的表达式只会被执行一次,得到访问对象后确定迭代的范围,在这个范围内进行遍历。
例如:
#include <iostream>
#include <vector>
#include <cstdlib>
using namespace std;
vector<int> v = {1, 2, 3, 4, 5, 6};
vector<int> &getRange()
{
cout << "get vector range..." << endl;
return v;
}
int main(void)
{
for (auto val : getRange())
{
cout << val << " ";
}
cout << endl;
system("pause");
return 0;
}此函数只会被执行一次。
此外,范围for的变量需要在其内部声明,不可引用全局变量。
函数内终止程序
exit(0);函数重载
函数的参数个数、参数类型、参数顺序不同三者中满足其中一个,就是函数重载。
函数重载可以通过一个函数名根据参数的不同执行多个操作。
异或1
假如一个偶数异或1,那么得到的结果是偶数+1.
如果一个奇数异或1,那么得到的结果是奇数-1。
无论正负。
加快读入
ios::sync_with_stdio(false),cin.tie(0);cin.tie与sync_with_stdio加速输入输出-码农场 (hankcs.com)
(41条消息) 【C++】ios_base::sync_with_stdio(false) 和 cin.tie(NULL)_sync with stdio_大熊の笔记的博客-CSDN博客
异或交换变量值
只需要一下三步:
a=a^b;
b=a^b;
a=a^b;前两步做完:
a=a^b;
b=a;最后一步:
a=a^b^a=b;scanf循环读入
while(scanf("%d",&n),n)
{
}这里为逗号表达式,若干项之间由逗号隔开,值为表达式的最后一项。
当然也可以直接 while(cin >> n)
Vector判重
sort(vec.begin(),vec.end());
vec.erase(unique(vec.begin(),vec.end()),vec.end());其中,unique函数返回值为去重后的序列的下一个元素的迭代器,而去重并不是真正的去重,只是把重复的都丢到了容易尾部而已,所以要把后面的都删掉。
unique函数从头到尾扫一遍,只是把每个元素和上一个元素比较是否重复,所以使用之前记得sort一遍。
求和函数
int sum = accumulate(vec.begin() , vec.end() , 42); 第三个参数为初始值。
Memset
memset(s,ASCII,size);表示把指针 开始往后 个字节大小全部赋值为 ASCII,如果是 char 类型,那么就可以直接赋值为对应 ASCII 的字符,因为 char 的内存占用为 字节,而 的话对应四个字节,每个i字节对应 会导致二进制下重复了四次,所以就会导致赋值后不是原来的数。
比如常见的 0x3f 就变成了 0x3f3f3f3f,其中 0x 代表十六进制。
那么127就可以把除了符号位的前七位都补满,使它变成一个很大的数,而 -1 的补码全为1,这样就可以完成全部 -1 的赋值,同样 255 也可以做到全赋值为 -1。
而我们常见的 0x3f 就是常用的“无穷大”,它的值为 它的精妙之处在于它使得无穷大加上无穷大之后依然是无穷大,而 做不到,0x7fffffff 也做不到,那么无穷小呢?通常就会设为 使得其符号位为 ,但是这还是太小了,万一减去一个无穷小就变成无穷大了。
参考 0x3f ,经过简单的进制转换和推导,我们轻松得到了 的补码的 16进制表示为 0xc0c0c0c1,而 memset 的时候我们就可以直接设为 0xc0 就可以了,这样得到的值为 ,可以满足我们的需求。
补充:memset 的时候设为 ~0x3f 也有同样的效果。
Memcpy
int g[N], f[N];
memcpy(g, f, sizeof(f)); // 将 f 数组内的 sizof(f) 个字节复制到 g 数组中Strcpy
char a[100];
strcpy(a, "10212");Strstr
char a[100], b[100];
int res = strstr(a, b) - a; // 返回 b 在 a 中出现的第一个位置的指针,若不存在返回空指针,减去数组指针得到下标内存转换
其中 B 之前有一个 “i” 是表示这个是换算单位是 而非 ,通常也省略 “i”,这里与另一种作区分。
动态内存分配
一维:
int* arr;
int n;
scanf("%d",&n);
arr = (int*)malloc(sizeof(int)*n); // 分配n的空间
free(arr);二维:
#include<bits/stdc++.h>
using namespace std;
int main()
{
int **r;
int n,m;
scanf("%d%d",&n,&m);
r= (int**)(sizeof(int)*m);
for(int i = 0; i < m; ++i)
r[i] = (int*)malloc(sizeof(int)*n);
for(int i = 0; i < m; ++i)
free(r[i]);
free(r);
return 0;
}要记得 free。
库函数
builtin_popcount
__builtin_popconunt(x);返回 二进制下的 的个数。
__builtin_popcount(12); // 2与 bitset 里的 a.conut() 类似。
builtin_ctz
返回输入数的二进制表示下右起连续的零的个数(后导零长度)
__builtin_ctz(unsigned int x)
__builtin_ctz(unsigned long x)
__builtin_ctz(unsigned long long x)builtin_clz
返回该类型前导零的个数。
__builtin_clz(unsigned int x)
__builtin_clz(unsigned long x)
__builtin_clz(unsigned long long x)builtin_parity
判断该数二进制表示下 1 的个数的奇偶性,偶数返回 0,奇数返回 1
__builtin_parity(x)builtin_ffs
__builtin_ffs(x)返回最低的 1 的下标 + 1
builtin_sqrt
__builtin_sqrt(double x)快速开平方。
返回值为 double 类型。
Template
C模板template用法总结_c template-CSDN博客
可以理解为自动识别类型的函数/类。
结构体去重
unique()不过要先重载小于号进行排序,然后重载等于号才能进行判重。
Multiset 单点修改
正常情况下 erase 一个值会把所有的这个值给删除,那假如只想删去一个呢?
可以先 find 得到这个值的一个迭代器,然后 erase 这个迭代器即可。
/* CF1884D */
#include <bits/stdc++.h>
using namespace std;
multiset<int> ml, mr;
int main()
{
int T;
scanf("%d", &T);
while(T--)
{
char op[2];
scanf("%s", op);
int l, r;
scanf("%d%d", &l, &r);
if(*op == '-')
{
ml.erase(ml.find(l));
mr.erase(mr.find(r));
}
else
{
ml.insert(l);
mr.insert(r);
}
if(!ml.size())
{
cout << "NO" << endl;
}
else if(*(prev(ml.end())) > *mr.begin())
{
cout << "YES" << endl;
}
else
{
cout << "NO" << endl;
}
}
return 0;
}